


Морская болезнь, вызывающая такие симптомы, как тошнота, головокружение и зрительная усталость, является фундаментальной проблемой иммерсивной отрасли. Лёвенский университет в Бельгии опубликовал исследование, демонстрирующее, что сочетание данных отслеживания движений глаз и головы и облегчённой модели ансамблевого обучения обеспечивают эффективное и недорогое обнаружение укачивания в реальном времени. В ходе тестов на людях решение достигло точности в 93%.
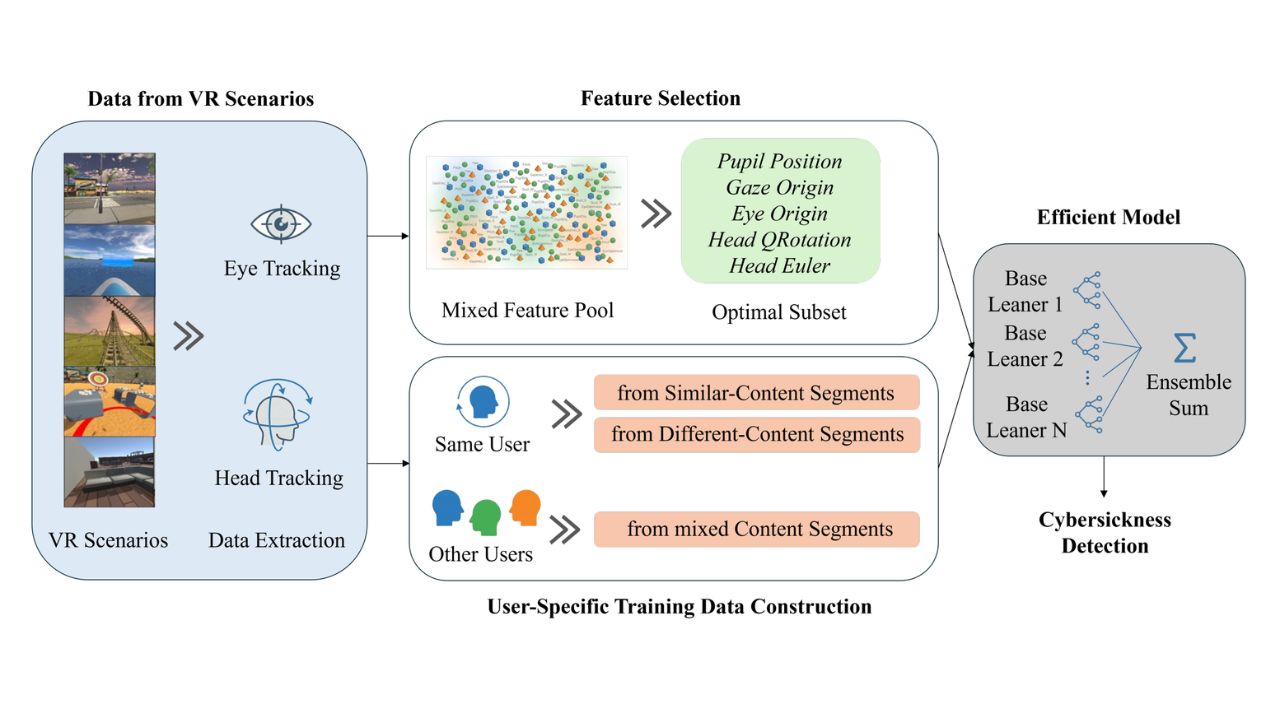
Существующие методы обнаружения укачивания в основном основаны на физиологических сигналах от систем ЭЭГ и ЭКГ, которые требуют дополнительных датчиков, включают сложные модели и требуют значительных вычислительных затрат. Исследовательская группа из Бельгии применила другой подход только со встроенными в очки датчиками движений глаз и головы. Путём отбора признаков авторы работы обнаружили 23 наиболее информативных признака, включая положение зрачка, точку начала взгляда, точку начала движения глаз и угол поворота головы. Они дают примерно 92% эффективности обнаружения.
Что касается выбора модели, команда сравнила различные модели глубокого обучения, такие как LSTM, GRU и CNN-LSTM, а также ансамблевые модели обучения, такие как Random Forest и XGBoost. Результаты показали, что ансамблевая модель XGBoost достигла средней точности 92% при 10-кратной перекрёстной проверке с более сбалансированными показателями F1 по четырём уровням укачивания (отсутствует, низкое, среднее и высокое). При этом время её обучения составляло всего несколько секунд, а время вывода — приблизительно 0,06 миллисекунды на образец. Прочие модели показали непостоянную производительность на одних и тех же данных и потребовали более длительного времени обучения.
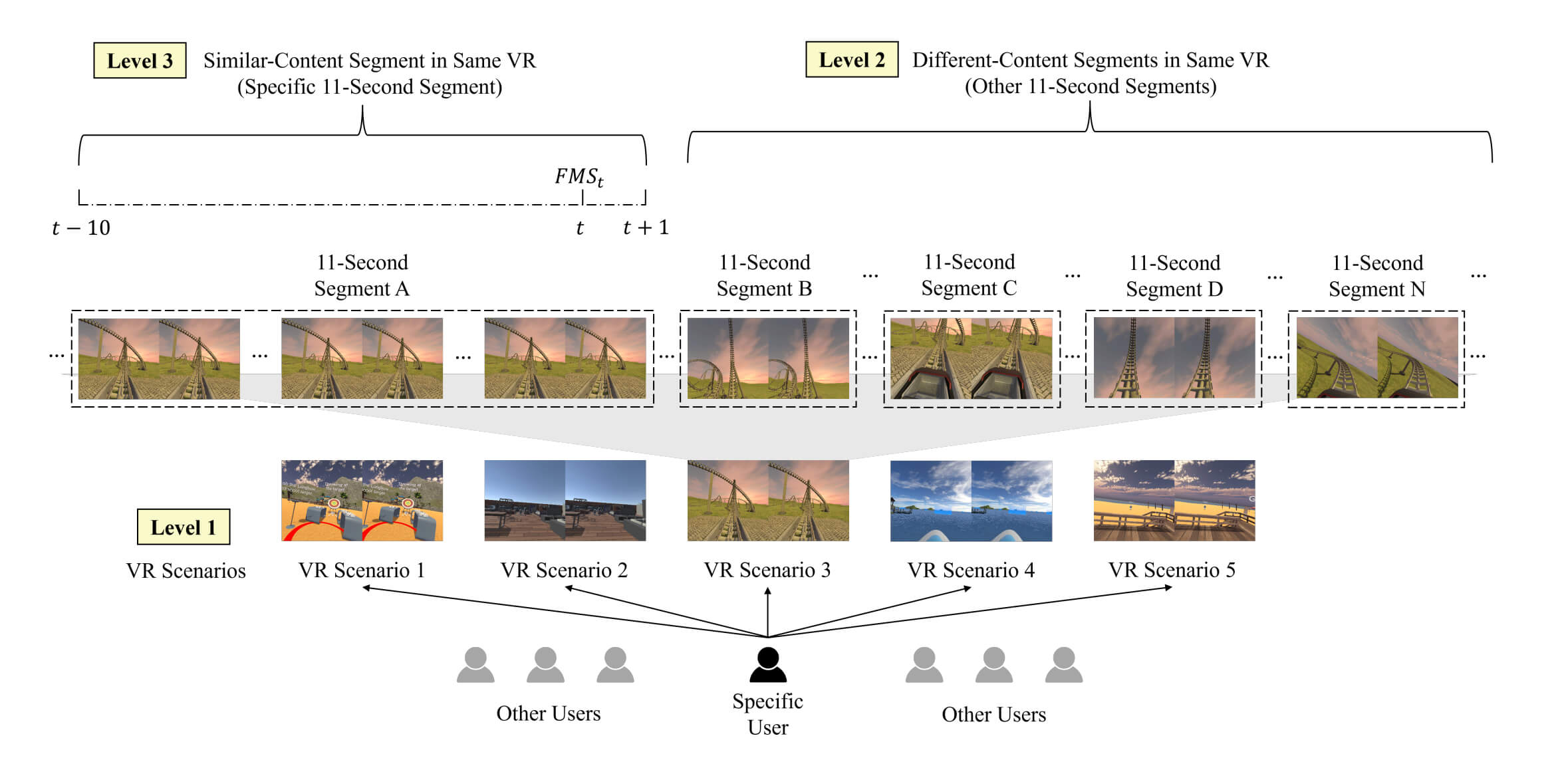
Морская болезнь характеризуется значительными индивидуальными различиями; некоторые пользователи испытывают лёгкий дискомфорт, в то время как другие практически не проявляют симптомов. Поэтому исследовательская группа разработала трёхступенчатую стратегию обучения с использованием данных, специфичных для каждого пользователя: первый уровень использует данные из разных ВР-сцен, второй уровень — данные из разных сегментов одной и той же сцены, а третий — данные из схожих сегментов одной сцены.
Эксперименты показывают, что обучение с использованием только данных третьего уровня (схожие сегменты) обеспечивает точность 94%; сочетание первого и третьего уровней приводит к точности 93% при обобщённых настройках на разных пользователях и достигает 88% при персонализации.
Команда дополнительно отобрала шесть пользователей с относительно сбалансированным распределением категорий для персонализированного обнаружения. Базовая модель, использующая только данные других пользователей, имела среднюю точность всего 65% и не могла определить низкий, средний или высокий уровень укачивания. После добавления данных пользователей по различным сценам (уровень 1) и похожим сегментам (уровень 3) средняя точность выросла до 88%, а показатели F1 на каждом уровне также значительно улучшились, при этом время обучения увеличилось всего на 0,15 секунды, а время вывода — всего на 0,011 миллисекунды.
Исследователи отмечают, что их подход полезен для реального применения: можно обучить общую базовую модель, используя большой объём данных от разных пользователей, а затем собрать небольшое количество данных отслеживания взгляда и головы от новых пользователей в различных сценариях виртуальной реальности, чтобы быстро персонализировать калибровку и получать предупреждения о укачивании в реальном времени во время сеанса. Кроме того, этот метод не требует дополнительных датчиков, имеет низкие вычислительные затраты и, как ожидается, станет эффективным инструментом для внутренней настройки комфорта в продуктах виртуальной реальности.
Однако важно отметить, что данное исследование основано на открытом наборе данных Simulation 2021, имеет ограниченный размер выборки и ещё не было проверено в реальной системе виртуальной реальности. Команда планирует протестировать его на более широком круге пользователей и в различных сценариях, а также изучить практические пути от общего предварительного обучения до тонкой персонализированной настройки.
Не пропускайте важнейшие новости о дополненной и виртуальной реальности — подписывайтесь на Голографику в Telegram, ВК и Twitter! Поддержите проект на Boosty.
Далее: Учёные разработали способ передавать запахи в мозг с помощью ультразвука
