

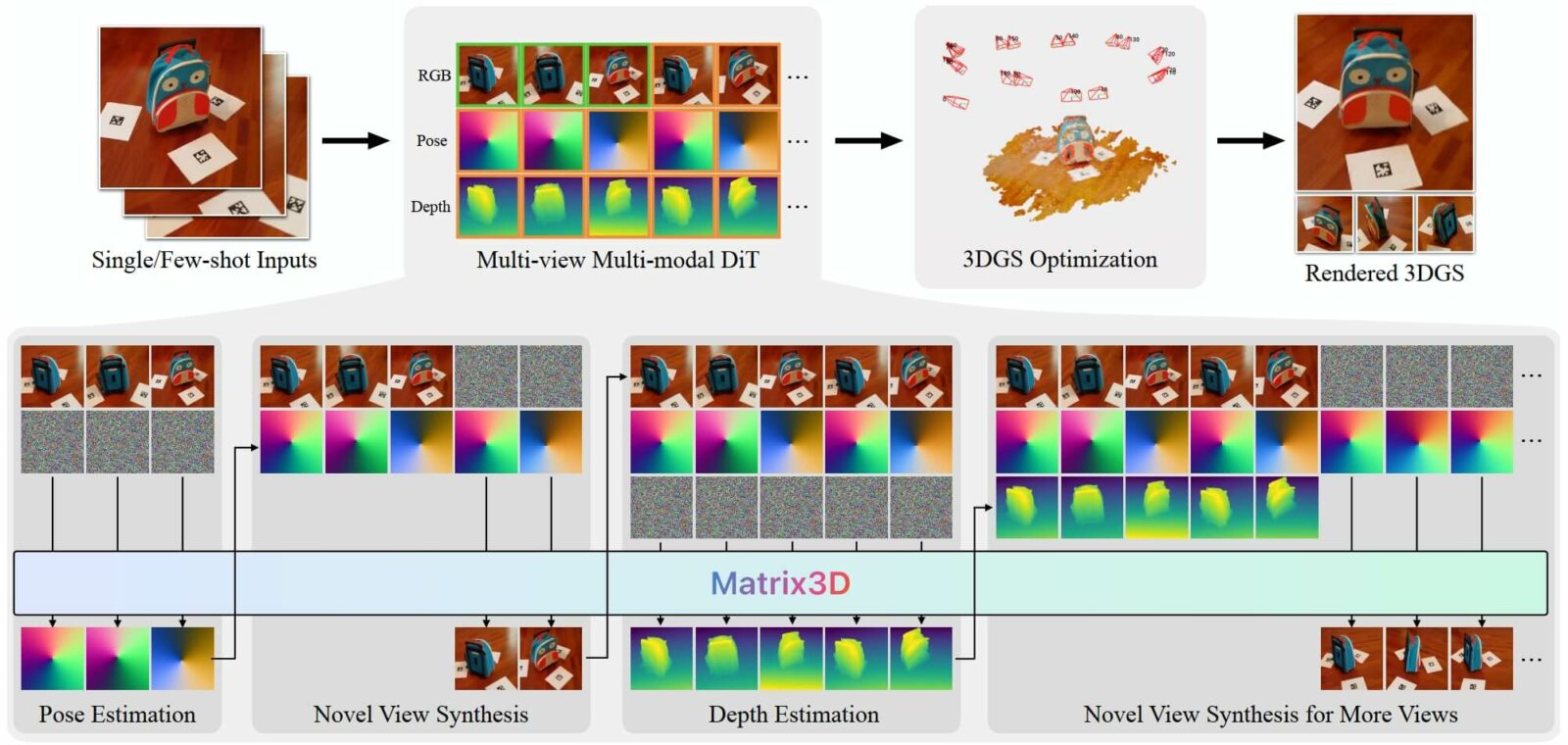
Группа инженеров из Университета Нанкина, Гонконгского университета науки и технологии и Apple представила нейросетевую модель Matrix3D, которая способна самостоятельно выполнять несколько подзадач фотограмметрии по одному или нескольким фото, включая оценку позиции, прогнозирование глубины и синтез новых ракурсов без дополнительных данных.
Новая технология упрощает конвейер фотограмметрии, который обычно состоит из нескольких инструментов. Для работы с разными типами входных данных, таких как изображения, параметры камеры и карты глубины, Matrix3D использует мультимодальный диффузионный преобразователь (Diffusion Transformer, DiT).
Ключ к обучению Matrix3D, пишут авторы, заключается в маскировании (Masked Autoencoder, MAE). Оно возможно даже с неполными данными, такими как бимодальные данные пар изображение-поза и изображение-глубина. Это расширяет потенциальный датасет и делает нейросеть более универсальной. Благодаря такому подходу она достраивает недостающие ракурсы и может прогнозировать глубину по трём кадрам.
Авторы проекта опубликовали код и веса модели в свободном доступе вместе с инструкцией. Согласно документации, успешное тестирование прошло в Ubuntu 20.04 с PyTorch 2.4 и Python 3.10. С отчётом о работе можно ознакомиться по ссылке.
Не пропускайте важнейшие новости о дополненной и виртуальной реальности — подписывайтесь на Голографику в Telegram, ВК и Twitter! Поддержите проект на Boosty.
Далее: MotionBlocks: учёные упростили движения в виаре для тех, кому они даются с трудом




