



ByteDance, китайская компания, стоящая за TikTok, разработала новый метод стирания лиц на видео для приложений дополненной реальности. Это решение позволяет менять конфигурации лиц и накладывать на них любую графику. Компания утверждает, что технология уже внедрена в коммерческие мобильные продукты, но не сообщает, в какие именно.
Примеры, представленные в новой статье исследователей ByteDance, иллюстрируют возможности метода в комичных, гротескных и пугающих конфигурациях:

В августе ByteDance сообщила, что видеохостинг «TikTok», первое приложение не от Facebook с треми миллиардами установок, выпустил закрытую бету Effect Studio, платформы для разработчиков дополненной реальности под видеоконтент. Так компания встаёт в один ряд не только с Facebook и её Spark AR, но и со Snap, которая предлагает редактор эффектов Lens Studio.
Авторы соответствующей научной статьи под заголовком «FaceEraser: Removing Facial Parts for Augmented Reality» («FaceEraser: удаление частей лиц для дополненной реальности») отмечают, что существующие алгоритмы, такие как NVIDIA SPADE, больше ориентированы на завершение усечённых или иным образом полузатенённых изображений, чем на выполнение необычной процедуры «очищения», поэтому существующие датасеты предсказуемо скудны.
Исследователи создали новую сетевую архитектуру «Pixel-Сlone», которую можно наложить на нынешние модели восстановления областей (inpainting). Она решает проблемы, связанные с несоответствиями текстуры и цвета в старых методах, таких как StructureFlow и EdgeConnect.
Чтобы обучить модель на «пустых» лицах, исследователи исключили изображения с очками или волосами, закрывающими лоб, поскольку область между волосами и бровями обычно является самой большой группой пикселей, которая может обеспечить материал для центральных областей лица.
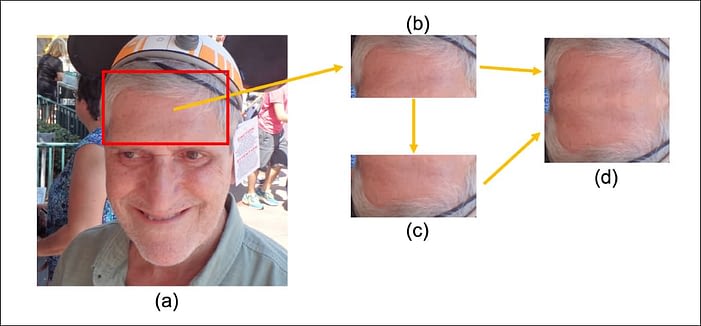
Получается изображение размером 256×256 пикселей, которое можно вводить в скрытое пространство нейросети партиями, достаточно большими для обобщения. Позднее алгоритмическое масштабирование восстанавливает разрешение, необходимое для работы в дополненной реальности.
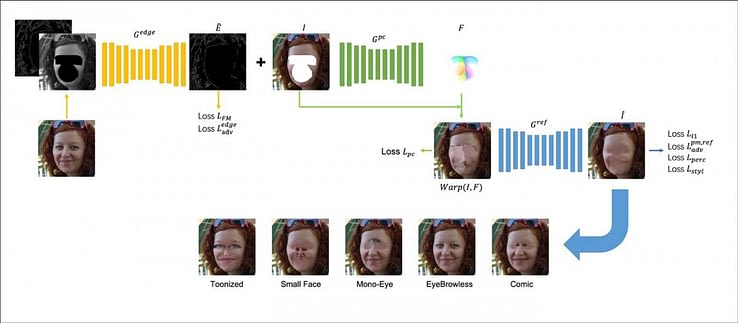
Сеть состоит из трёх внутренних сетей: Edge Completion, Pixel-Clone и сети уточнения. Edge Completion основана на архитектуре кодера-декодера того же типа, что и в EdgeConnect, а также в популярных дипфейк-приложениях. Кодеры дважды понижают разрешение изображения, а декодеры восстанавливают исходные размеры.
Pixel-Clone использует модифицированную методологию кодера-декодера, а слой уточнения работает на архитектуре «U-Net», которая первоначально разработана для биомедицинской визуализации.
Во время обучения необходимо оценивать точность преобразований и, при необходимости, повторять попытки итеративно вплоть до сходимости. Для этого используются два дискриминатора на основе PatchGAN, каждый из которых оценивает локализованный реализм участков размером 70×70 пикселей, не принимая во внимание значение реализма всего изображения.
Сеть Edge Completion обучается независимо, а две другие сети обучаются вместе, на основе весов, полученных в результате обучения первой.
Инженеры ByteDance утверждают, что «стёртые лица позволяют использовать различные приложения дополненной реальности, требующие размещения любых настраиваемых пользователем элементов». Это указывает на возможность работы со сценариями от пользователей.
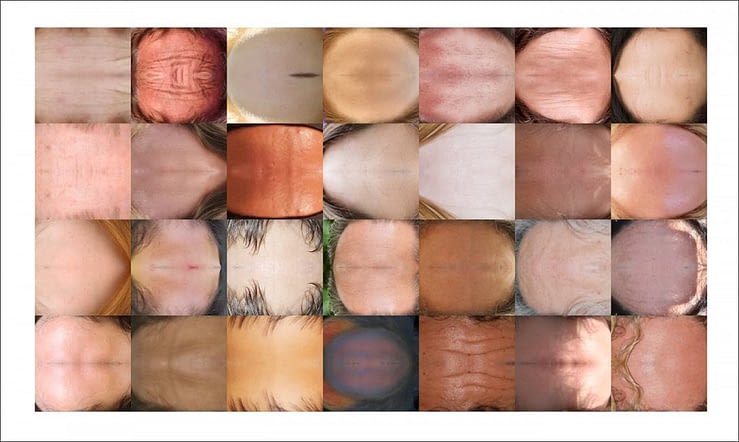
Модель обучается на масках из созданного NVIDIA набора данных «FFHQ», который содержит адекватное разнообразие возрастов, национальностей, освещения и мимики для достижения полезного обобщения. В датасете 35 000 изображений и 10 000 обучающих масок для определения областей трансформации; 4000 изображений и 1000 масок зарезервированы для проверки.
Обученная модель может выполнять логический вывод на основе данных из CelebA-HQ и VoxCeleb, новых лиц из FFHQ и любых других новых лиц. Изображения в формате 256×256 обучены партиями по восемь штук с помощью оптимизатора Adam, реализованного в PyTorch и запущенного на GPU Tesla V100 на 2 000 000 эпох.
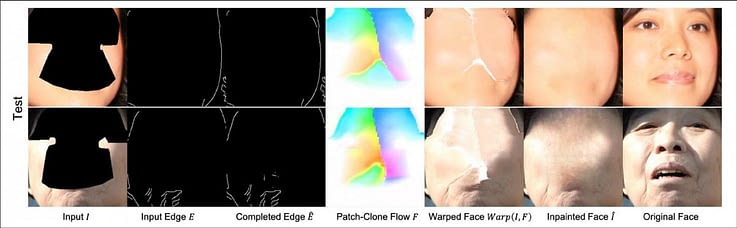
Как это часто бывает в исследованиях синтеза изображений на основе лиц, системе приходится бороться со случайными сбоями, вызванными препятствиями или окклюзиями, такими как волосы, периферийные устройства, очки и растительность на лице.
Не пропускайте важнейшие новости о дополненной и виртуальной реальности — подписывайтесь на Голографику в Telegram, ВК, Twitter и Facebook!
Далее: Qualcomm поглощает Wikitude
