


Современные системы виртуальной реальности отслеживают только положения головы и рук. Они знают, где находитесь вы и окружающие предметы и делают вроде бы логичные выводы о том, как вы выглядите в пространстве. Так кажется до тех пор, пока вы не увидите свой ростовой аватар с туловищем, ногами и локтями.
Следить за ними с помощью дополнительных датчиков дорого и неудобно, поэтому здесь применяют так называемую инверсную кинематику, ИИ-алгоритмы для предположения поз «невидимых» участков тела на основе известных опосредованных данных. Сегодня они не готовы к уверенному решению проблемы трекинга всего тела.
Причина в том, что существует слишком много потенциальных выводов для каждого набора положений головы и рук. Ограничения инвестор кинематики продолжают плодить приложения, в которых видно только руки и верхнюю половину туловища.
В прошлом году учёные Meta* показали нейросетевую модель QuestSim, которая может оценить правдоподобную позу всего тела, используя только данные отслеживания с Quest 2 и их контроллеров. У неё есть ограничения, которые удалось обойти другой команде в проекте AGRoL.
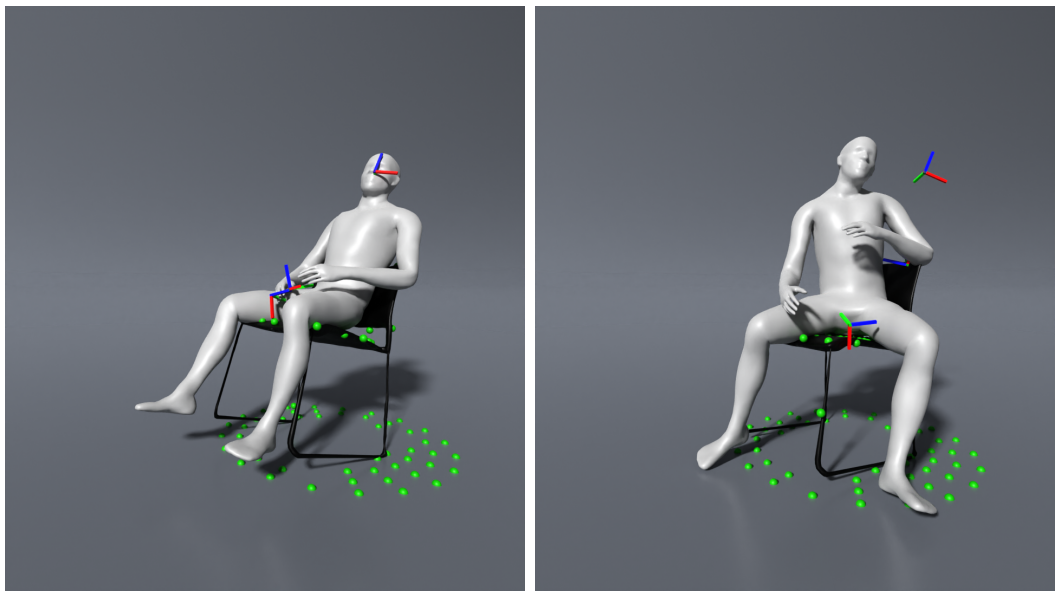
Слепым пятном в моделях оказалось взаимодействие с реальным миром, такое как переход в сидячее положение и из него, а также действия, производимые сидя. Между тем обработка этих нюансов имеет большое значение для реалистичности поведения аватаров, особенно в социальных сценариях.
В новой статье под названием QuestEnvSim три исследователя из проекта QuestSim с коллегами из Национального университета Сеула представили обновлённый набор моделей с использованием подхода к обучению с подкреплением из прошлогодней работы с учётом мебели и других реальных объектов.
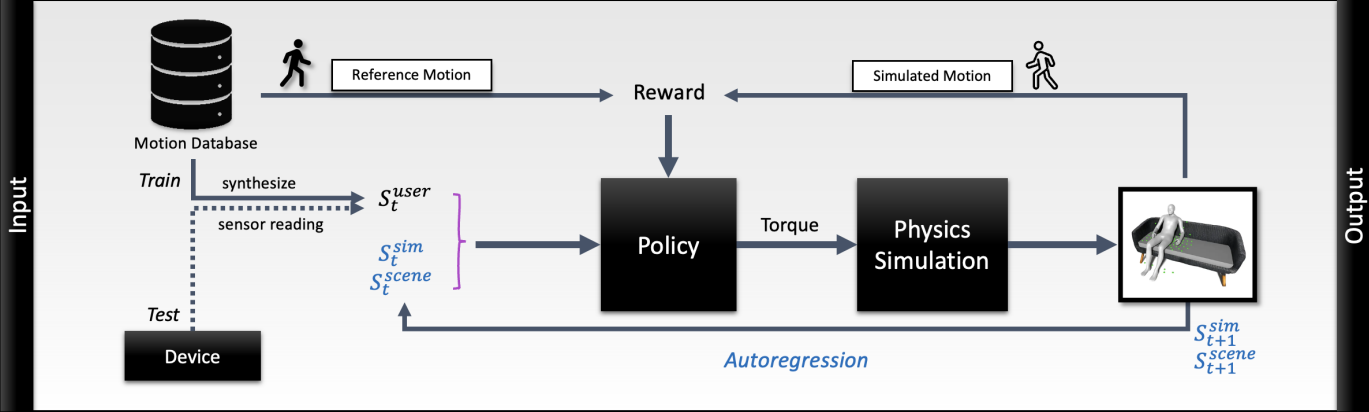
Результаты можно оценить на видео. В целом они впечатляют, но авторы QuestEnvSim призывают не ожидать скорого внедрения в мобильный софт. Решение не будет работать на Quest в ближайшее время.
В документе снова не упоминается производительность системы, выполняющей расчёты. Для такого результата в реальном времени может потребоваться мощное стационарное оборудование на основе графических или нейросетевых ускорителей.
Во-вторых, разреженная карта глубины для используемой мебели и предметов была вручную размещена в виртуальной среде. Если Quest 3, возможно, будут способны автоматически сканировать мебель с помощью лидара, у Quest 2 и Quest Pro таких датчиков нет.

Наконец, система предназначена для правдоподобной оценки общей позы тела, а не для точного соответствия положению ваших рук, а задержка в эксперименте эквивалентна множеству кадров. Таким образом, разработка в нынешнем виде не подходит для массового виара, даже если может функционировать в реальном времени.
Однако дальнейшая оптимизация, добавление других алгоритмов в комплекс и рост мощности клиентских устройств позволяют надеяться на постепенное проникновение нейросетей на очки и получение результатов, достойных применения в социальных и игровых приложениях.
Подробнее с QuestEnvSim вы можете ознакомиться в отчётной статье разработчиков этой технологии.
*В России признана экстремистской организацией
Не пропускайте важнейшие новости о дополненной и виртуальной реальности — подписывайтесь на Голографику в Telegram, ВК и Twitter! Поддержите проект на Boosty.
Далее: Unigine 2.1.7 пополнился серией улучшений, включая панорамное глобальное освещение и IG+VR Template
