


Сегментация — определение того, какие пиксели изображения принадлежат объекту — является одной из базовых задач компьютерного зрения. Решать её приходится в широком спектре приложений, от анализа видео и аудио до редактирования и дополнения материалов новыми цифровыми данными. Но создание точной модели сегментации для конкретных задач обычно требует узконаправленной работы дорогих технических экспертов с доступом к инфраструктуре обучения ИИ и большим объёмам аннотированных данных по предметной области.
В ходе своих разработок по компьютерному зрению, лежащих в основе стратегии метавселенной, Meta* представила проект Segment Anything, а именно новую нейросетевую модель Segment Anything Model (SAM) и набор данных Segment Anything 1-Billion mask (SA-1B). Представители компании уверяют, что это крупнейший из когда-либо созданных датасетов сегментации, который может сработать для самых разных применений и способствует дальнейшим исследованиям базовых моделей для компьютерного зрения.

Компания выложила датасет и модель в открытый доступ: SA-1B разрешили использовать в исследовательских целях, а SAM — по открытой лицензии Apache 2.0.
Проект Segment Anything имеет целью сокращение потребности в экспертных знаниях по моделированию, машинному обучению и аннотированию данных. Разработчики хотели построить базовую модель для сегментации изображений: модель с подсказками, которая обучается на разнообразных данных и может адаптироваться к задачам — аналогично тому, как подсказки используются в моделях обработки естественного языка, таких как ChatGPT. Однако необходимые обучающие данные недоступны онлайн или где-либо ещё, в отличие от изображений, видео и текста, которых в интернете предостаточно. Поэтому вместе с моделью Meta пришлось создать набор данных беспрецедентного масштаба.
SAM получила общее представление об объектах и может генерировать маски для любого объекта на любом изображении или видео, включая объекты и типы изображений, с которыми сеть не сталкивалась во время обучения. Она достаточно универсальна, чтобы охватить разные варианты применения, и её можно использовать «из коробки» на новых типах изображений — будь то подводные фотографии или клеточная микроскопия — без дополнительного обучения.
 Среди прочих сценариев Meta, к примеру, предлагает использовать SAM в области дополненной и виртуальной реальности. Нейросеть может выделять объекты из поля зрения камер очков, чтобы использовать их как трёхмерные модели, добавлять графику, давать человеку справки по окружению и следить за процессами.
Среди прочих сценариев Meta, к примеру, предлагает использовать SAM в области дополненной и виртуальной реальности. Нейросеть может выделять объекты из поля зрения камер очков, чтобы использовать их как трёхмерные модели, добавлять графику, давать человеку справки по окружению и следить за процессами.
Обобщение подходов
Раньше для решения любой задачи сегментации существовало два класса подходов, пишут авторы проекта. Первый, интерактивная сегментация, позволял сегментировать любой класс объектов, но требовал, чтобы человек руководил методом путём итеративного уточнения границ. Второй, автоматическая сегментация, позволял выделять заранее определённые категории объектов (например, кошки или стулья), но требовал значительного количества выделенных вручную объектов для обучения (например, тысячи или даже десятки тысяч фотографий кошек) наряду с вычислительными ресурсами и техническими знаниями по тренировке модели. Ни один из подходов не обеспечивал полной автоматизации.

SAM объединяет оба подхода. Это модель, которая может легко выполнять как интерактивную, так и автоматическую сегментацию. Интерфейс позволяет гибко использовать её, просто давая правильные подсказки (клики, рамки, текст и так далее). Кроме того SAM обучалась на разнообразном и высококачественном наборе данных из более чем миллиарда масок, собранных в рамках проекта. Это позволяет обобщать новые типы объектов и изображений, выходящие за рамки наблюдений. Такая способность означает, что специалистам-практикам не нужно собирать собственные данные сегментации и настраивать модель для уникального применения.
В совокупности эти возможности позволяют SAM обобщать как новые задачи, так и новые домены. Авторы Segment Anything говорят, что такая гибкость впервые встречается в области сегментации изображений.
Основные возможности SAM:
- Выделение объектов кликами с интерактивной анимацией или рамкой
- Вывод нескольких потенциальных масок при неопределённости
- Автоматический поиск всех объектов на изображении
- Работа в реальном времени
Как работает SAM: быстрая сегментация
В обработке естественного языка, а в последнее время и в компьютерном зрении, одним из самых захватывающих достижений является создание базовых моделей, которые могут выполнять обучение с нулевым или малым количеством практики для новых наборов данных и задач с использованием подсказывающих запросов.
Авторы SAM научили её отдавать валидную маску сегментации для любого запроса, который подсказывает решение точками переднего плана/фона, грубой рамкой, текстом произвольной формы или вообще любой информацией, указывающей, что сегментировать в изображении. Получение валидной маски означает, что даже если подсказка неоднозначна и может относиться к нескольким объектам (например, точка на рубашке может указывать либо на рубашку, либо на человека, который её носит), вывод должен быть разумным для одного из этих объектов.

Но задача предварительной подготовки и интерактивный сбор данных наложили ограничения на дизайн модели. В частности, модель должна работать в реальном времени на центральном процессоре в веб-браузере. Ограничение времени выполнения подразумевает компромисс между качеством и скоростью, но разработчики обнаружили, что простой дизайн даёт хорошие результаты на практике.
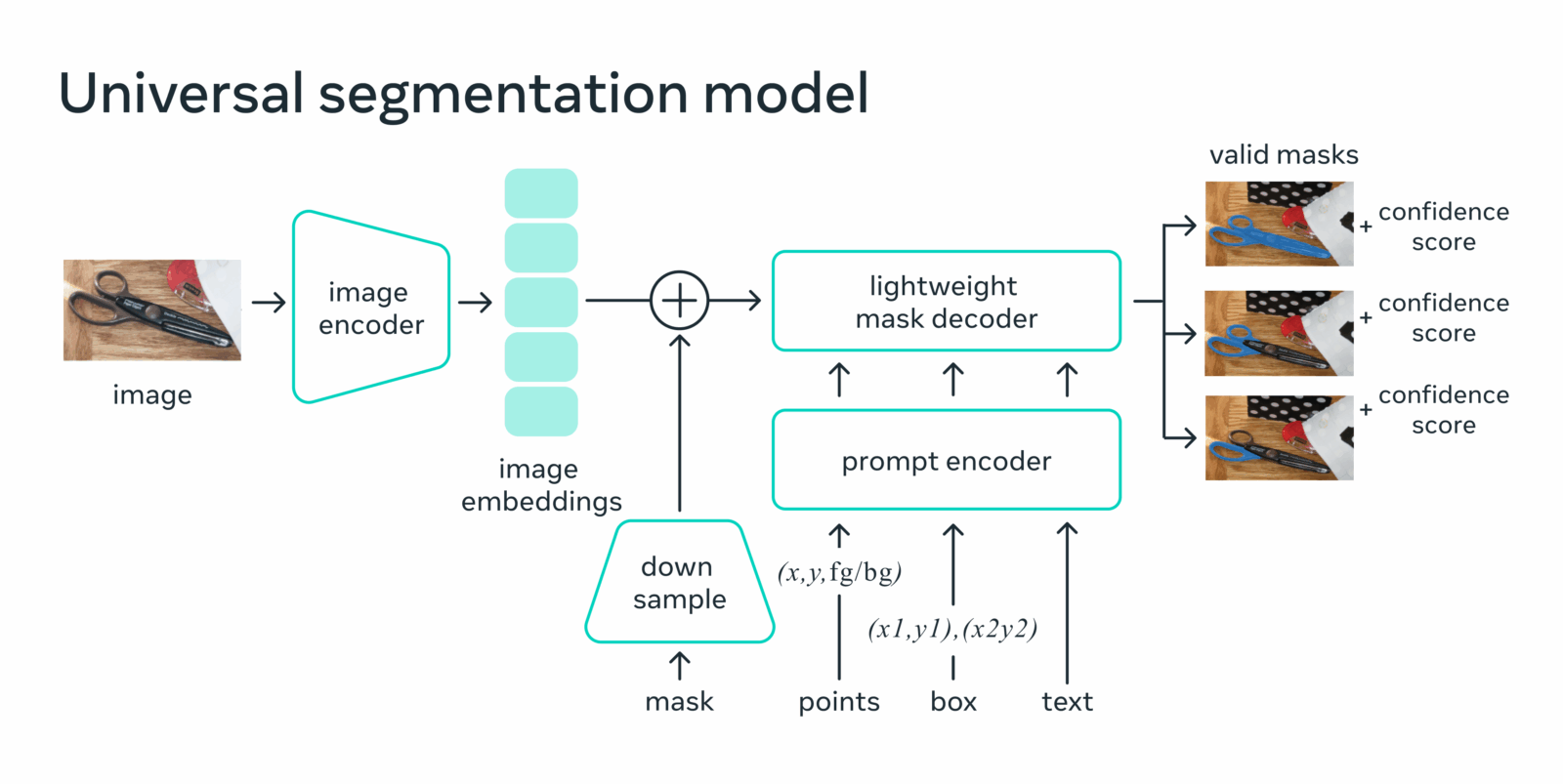
Под капотом кодировщик изображения делает векторную характеристику изображения, а его облегчённый аналог преобразует то же самое для подсказок. Затем два источника информации объединяются в упрощённом декодере, который определяет маски сегментации. После вычислений эмбеддинга SAM может выделить объект всего за 50 миллисекунд при любом запросе в браузере.
Сегментация миллиарда масок: создание SA-1B
Для обучения модели понадобился массивный и разнообразный источник данных. Публикуемый компанией датасет заявлен как самый большой в своей области на сегодняшний день. Участники проекта собирали информацию с помощью SAM. В частности, они использовали SAM для интерактивного аннотирования изображений, а затем направляли аннотированные данные на обновления модели. Для итеративного улучшения этот цикл повторяли много раз.
SAM ускоряет сбор новых масок. Интерактивное аннотирование маски занимает около 14 секунд. Процесс аннотирования всего вдвое медленнее выделения прямоугольными рамками, которое с использованием самых быстрых интерфейсов занимает около 7 секунд. Если сравнивать с другими подобными проектами, новая модель работает в 6,5 раз быстрее, чем полностью ручная аннотация в COCO на основе полигональной маски, и в 2 раза быстрее, чем предыдущая крупнейшая попытка аннотирования данных — тоже с помощью модели.
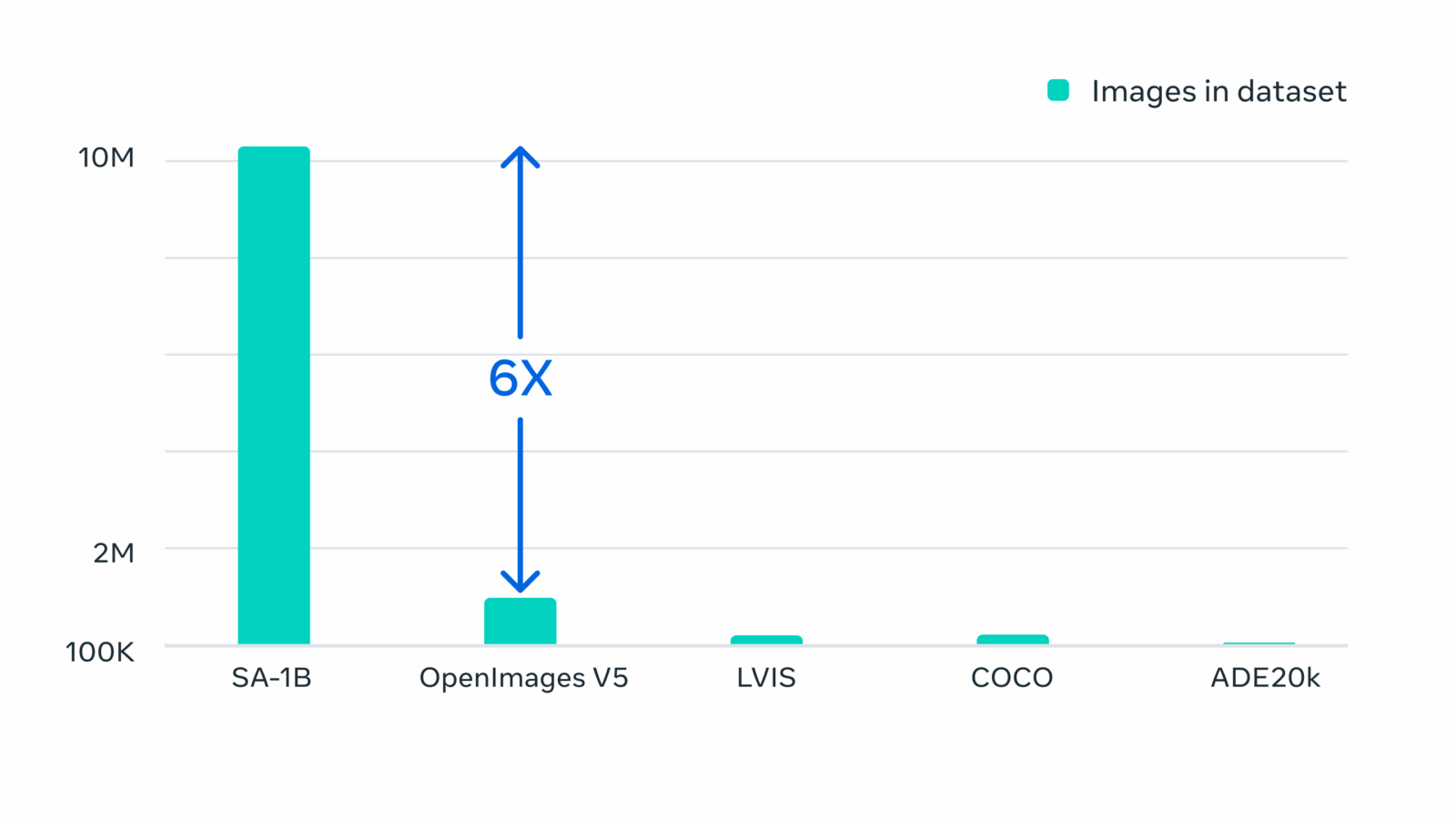
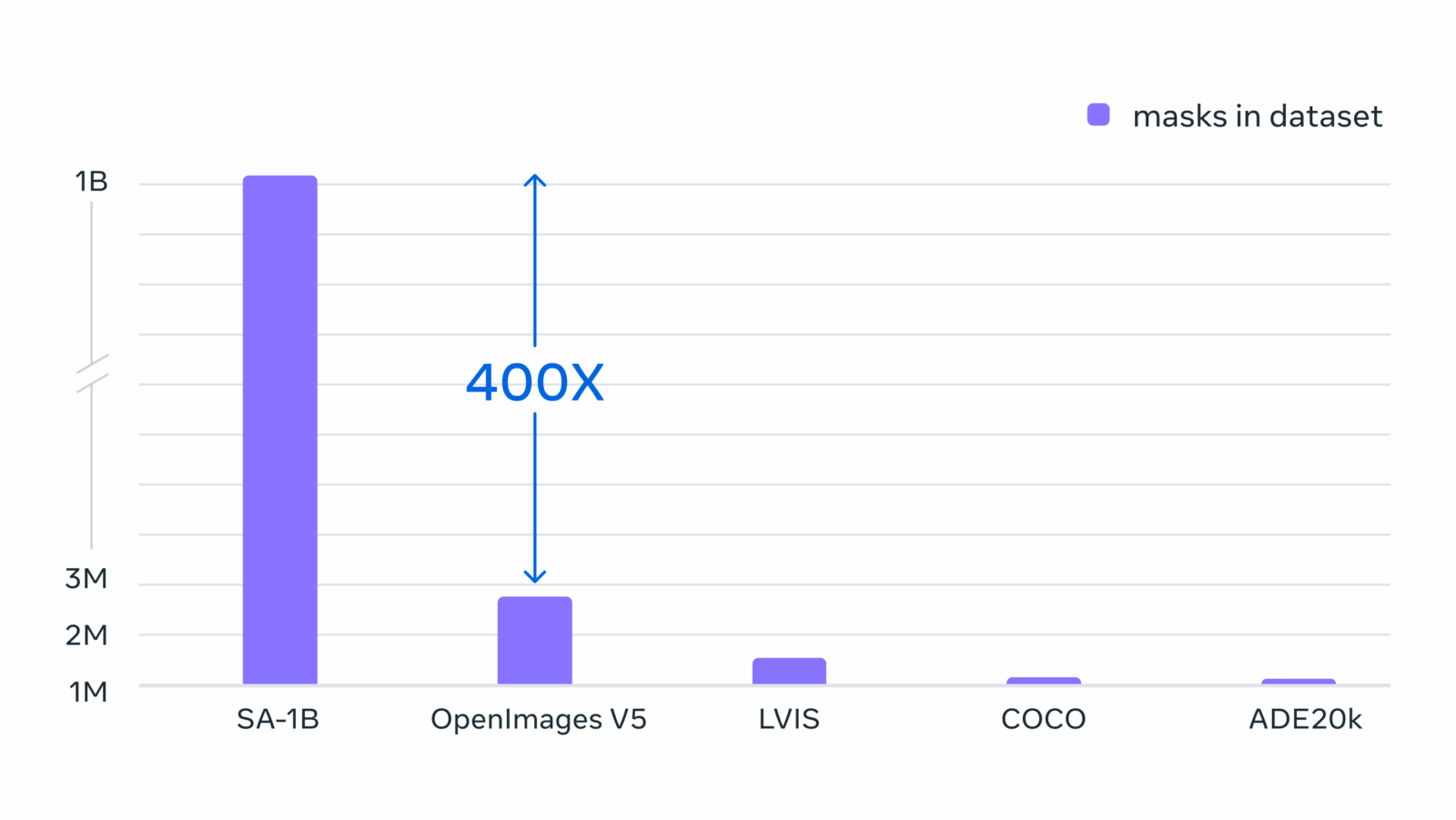
Однако интерактивное аннотирование плохо масштабируется для создания набора в миллиард масок. Поэтому разработчики SA-1B создали особый механизм сбора. У него три «передачи»: на первой модель помогает людям, как описано выше; вторая представляет собой сочетание автоматического аннотирования и работы человека, что увеличивает разнообразие собираемых масок; последняя полностью автоматическая и помогает масштабировать датасет.
Окончательный набор включает более 1,1 миллиарда масок, собранных на примерно 11 миллионах лицензированных и конфиденциальных изображений. У SA-1B в 400 раз больше масок, чем у любого аналога. В некоторых случаях они сравнимы по качеству с масками из гораздо меньших наборов, собранных вручную.

Изображения для SA-1B получены через поставщика фотографий из разных стран. Они охватывают разнообразный набор географических регионов и уровней дохода. В Meta отметили, что понимают нехватку информации по некоторым регионам, но это всё равно лучше предыдущих попыток. Кроме того, авторы проанализировали возможные отклонения модели в отношении воспринимаемого гендерного, расового и возрастного разнообразия и заключили, что SAM работает одинаково для разных групп людей. Есть надежда, что модель проявит стабильность в рабочем использовании.
Meta предлагает SA-1B для обучения базовых моделей, а также в качестве основы и дополнения других наборов. Нейросетевая модель проекта Segment Anything уже сегодня может стать частью первых ИИ-приложений нового уровня для очков виртуальной и дополненной реальности.
Начать легко. Meta опубликовала демонстрацию проекта, подробную информацию о датасете, код SAM на GitHub и подробное описание проделанной работы.
*В России признана экстремистской организацией
Не пропускайте важнейшие новости о дополненной и виртуальной реальности — подписывайтесь на Голографику в Telegram, ВК и Twitter! Поддержите проект на Boosty.
Далее: Обновление OpenXR Toolkit принесло трекинг глаз на Quest Pro




